0. Abstract
GoogLeNet은 ILSVRC14에서 SoTA를 달성한 모델로, 22층으로 이루어진 CNN입니다. Inception 아키텍처와 컴퓨팅 비용을 일정하게 유지하면서 네트워크의 크기를 키울 수 있는 디자인으로 자원을 더 효율적으로 사용하는 것이 가장 큰 특징입니다.
또한, 성능 최적화를 위해 Hebbian Principle과 Multi-Scale Processing에 기반한 디자인을 사용했습니다.
- Hebbian Principle
“Neurons that fire together, wire together.”
두 뉴런이 동시에, 지속적으로 활성화 되면 두 뉴런의 커넥션이 더 강해진다는 원리로, 1949년에 Donald Hebb이 제안했습니다. 인간의 학습과 기억의 기반이 되는 것으로 추정됩니다. - Multi-Scale Processing
Local detail과 global structure를 모두 얻기 위해 정보를 서로 다른 스케일이나 화질에서 분석하는 것으로, AI, 컴퓨터 비전 등에서 필수적으로 사용되는 기법입니다.
1. Introduction
2010년부터 2014년까지 image recognition과 object detection의 성능은 굉장한 속도로 증가했습니다. 단순히 하드웨어의 발전이나 더 큰 데이터셋, 더 큰 모델에만 의한 것이 아니라 새로운 아이디어, 알고리즘, 네트워크 구조로 인한 영향이 가장 컸습니다.
GoogLeNet의 특징은 다음과 같습니다:
- AlexNet보다 좋은 성능, 12배 적은 파라미터를 사용
- 더 큰 모델이나 네트워크뿐만 아니라, 딥러닝 아키텍처와 R-CNN 알고리즘 같은 고전적인 컴퓨터 비전의 시너지로 높은 성능 달성
- 효율성을 위해 추론 시 곱셈과 덧셈의 연산 상한선을 150억 번으로 제한
2. Motivation and High Level Considerations
모델의 성능을 높이는 가장 직관적인 방법은 크기를 늘리는 것입니다. 하지만 이 방법은 과적합을 유발할 수 있고, 학습 시간이 증가한다는 단점이 있습니다.

이 두 문제를 모두 해결할 수 있는 방법은 fully-connected에서 sparse connection으로 전환하는 것입니다. 기존 방식보다 커넥션이 적기 때문에 자연스럽게 요구되는 컴퓨팅 자원과 과적합의 위험도 줄어드는 것이죠.
Sparse connectivity는 그림과 같이 모든 뉴런이 서로 연결되지 않는 구조를 의미합니다. Arora et al.은 데이터셋의 확률 분포가 sparse할 경우, 최적의 네트워크를 단계적으로 구성할 수 있다고 제안했습니다. 즉, 특정 특징에 대해 활성화되는 뉴런의 집합을 찾고, 해당 뉴런들을 중심으로 네트워크를 형성하는 방식입니다. 이는 앞서 언급한 Hebbian principle과 유사하며, 우리 뇌가 뉴런을 연결하는 방식과도 비슷한 메커니즘을 따릅니다.
하지만 컴퓨터는 일관적이지 않은 sparse 데이터를 처리하는 데 굉장히 비효율적입니다. 산술 연산이 100배가 줄어들더라도 검색과 cache miss에 소요되는 시간이 매우 크기 때문에 sparse connection으로 전환하는 것이 사실상 의미가 없습니다.
저자들은 이 문제를 해결하기 위해 Inception 아키텍처를 도입했습니다. Inception은 Arora et al.의 연구를 토대로 sparse 네트워크를 근사하는 방식으로 설계됐으며, 실제로 성능이 개선된 부분이 있었습니다. 또한, 제한된 범위 내에선 최적의 구조였습니다.
- Cache miss 발생 이유
컴퓨터는 효율적인 메모리 접근을 위해 캐싱을 사용하는데, sparse matrix의 경우, 모델의 연산에 관여하지 않는 0이 대부분입니다. 캐시는 replacement algorithm을 사용하는데, 그 예시로 LRU(Least Recently Used) 알고리즘이 있습니다. 만약 0이 계속 발생해서 캐시에 0이 차 있다면 non-zero 값을 가져오기 위해 캐시보다 훨씬 느린 메모리에서 가져와야 하기 때문에 cache miss overhead가 발생하는 것입니다. - 어떻게 sparse 네트워크를 근사했을까?
앞서 언급했던 것처럼, 기존 컴퓨터는 dense 행렬을 처리하는 데 최적화 되어 있습니다. 따라서 sparse한 행렬을 클러스터링하여 dense한 submatrix를 만드는 방식으로 문제에 접근한 것입니다.
$$ \begin{bmatrix} 1 & 0 & 0 & 0 & 2 & 3 \\ 0 & 0 & 0 & 0 & 0 & 0 \\ 0 & 4 & 5 & 0 & 0 & 0 \\ 0 & 0 & 0 & 6 & 7 & 0 \\ 0 & 0 & 0 & 0 & 0 & 0 \\ 8 & 0 & 0 & 0 & 9 & 10 \end{bmatrix} \rightarrow \begin{bmatrix} 2 & 3 \\ 0 & 0 \end{bmatrix}, \begin{bmatrix} 4 & 5 \\ 0 & 0 \end{bmatrix}, \begin{bmatrix} 6 & 7 \\ 0&0 \end{bmatrix}$$
예를 들어 위와 같은 sparse 행렬이 있다고 가정했을 때, 4개의 dense submatrix로 클러스터링을 할 수 있는 것이죠. 더 자세한 내용은 다음 섹션에서 설명하도록 하겠습니다.
3. Architectural Details
Inception 구조의 핵심은 기존의 dense components(dense layers, convolutions, etc)로부터 sparse한 지역 최적 구조(optimal local sparse structure)를 근사하는 방법을 찾는 것입니다.
이 구조를 근사하는 방법에 대해 Arora et al.은 다음과 같은 과정을 제시했습니다:
- 마지막 층에서 뉴런간 상호 관계 분석
- 상호 관계가 높은 뉴런끼리 클러스터링
- 각 클러스터를 다음 층의 입력으로, 이전 층의 출력으로 사용
이렇게 완성된 네트워크에서 입력과 가까운 뉴런은 선이나 모서리처럼 국소적인 특징을 추출하기 때문에 1x1 convolution으로 충분한 정보를 추출할 수 있습니다. 하지만 층이 더 깊어질수록 더 큰 특징(e.g., 얼굴, 눈 등)을 추출하기 때문에 때문에 비교적 넓은 범위에 적용되는 3x3, 5x5 convolution이 이루어집니다.
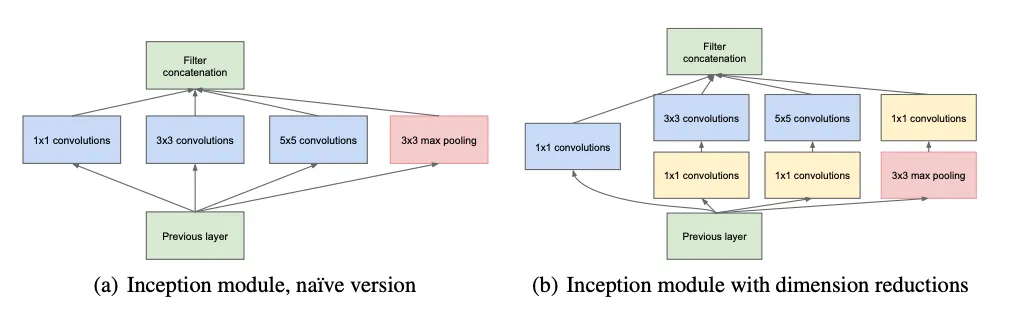
또한, 특징이 커질수록 해당 특징 내에서의 상관관계는 낮아지기 때문에 깊이 들어갈수록 더 많은 3x3, 5x5 convolution이 필요합니다. 그런데, (a)처럼 큰 패치에 대해 5x5 convolution을 하는 것은 많은 연산량($H_{out} * W_{out} * \text{in channels} * 5 * 5 * \text{out channels}$)을 요구하기 때문에 최적 구조라 하더라도 더 효율적인 구조가 필요합니다.
기존 정보를 유지하면서 연산량을 줄이기 위해 1x1 convolution과 projection으로 채널 수를 줄이는 방법이 있습니다. (b)는 이 방법을 활용하는 구조로, 연산량이 일정 수준을 넘어서지 않도록 하는 방식입니다. (차원 축소 외에도 비선형성을 부여하는 방법이기도 합니다. ex: convolution 후에 ReLU 적용)

이렇게 설계된 Inception 구조는 CNN 네트워크와 Inception 모듈 층이 결합된 방식으로, 다음과 같은 특징이 있습니다:
- 네트워크의 크기를 늘리면서도 학습 시간을 합리적인 수준으로 유지
- Non-Inception 구조를 사용하는 네트워크보다 2-3배 빠름
4. GoogLeNet

위 표는 GoogLeNet의 구조를 표로 나타낸 것으로, 22개의 층(풀링 포함 27층)으로 이루어져 있으며, 224x224x3 이미지를 입력으로 받습니다.
또한, linear 대신 avg pool 층을 사용함으로써 top-1 정확도를 0.6%가량 개선할 수 있었다고 합니다. 그리고 비교적 낮은 층에서 좋은 성능을 나타냈는데, 이는 중간 층에서도 구별되는 특징이 추출되었다는 것을 의미합니다. 따라서 (4a), (4d) Inception 모듈의 출력에 보조 classifier(CNN)를 적용해 학습에 사용했습니다.
- 보조 classifier와 역전파
모델이 22층으로 비교적 크기 때문에 역전파 과정에서 기울기 소실 문제가 발생할 수 있습니다. 논문에서는 보조 classifier를 사용함으로써 추가적인 loss 값을 구했고, 여기에 0.3을 곱한 값을 학습에 사용함으로써 문제를 해결할 수 있었습니다.
이 classifier는 다음과 같이 구성되어 있습니다.
- avg pooling: kernel=5, stride=3, output=4x4x512(4a), 4x4x528(4d)
- 1x1 conv: out_channels=128, ReLU
- fully connected layer: 1024 units, ReLU
- dropout layer: 70% dropped out
- softmax - 모델의 전체 구조

5. Training Methodology
GoogLeNet은 TensorFlow 전에 사용하던 DistBelief 프레임워크를 사용했습니다. 학습에서 사용한 하이퍼파라미터 값은 다음과 같습니다.
- 학습 방식: Asynchronous SGD
- momentum: 0.9
- learning rate 스케줄링: 8 에포크마다 4% 감소
- Polyak averaging으로 일반화
Asynchronous SGD의 본질은 일반적인 SGD와 동일합니다. 하지만 parallelism을 위해 각 작업자에게 서로 다른 미니배치를 할당하고, 서로 독립적으로 가중치를 업데이트함으로써 더 빠른 시간에 학습을 하는 것입니다. 하지만 각 작업자가 독립적으로 모델을 업데이트하기 때문에 업데이트 전 가중치를 사용하는 stale gradient 문제가 발생하기도 합니다.
Polyak averaging은 모델의 가중치에 포함된 노이즈를 줄이는 기법입니다.
$$ W_{avg,t}=\alpha W_{avg,t−1}+(1−\alpha)W_t $$
- $W_{avg, t}$: iteration $t$일 때 가중치의 평균값
- $W_t$: iteration $t$일 때 가중치
- $\alpha$: 하이퍼파라미터로, 주로 0.99처럼 1에 가까운 값으로 설정
논문에서는 매 iteration마다 Polyak averaging을 적용했다고 합니다. (조금의 성능 향상이 있을 수 있지만, 잘 사용하지 않는다고 해요)
이 외에도 이미지 자르기, 크기 변환 등 다양한 환경에서 모델을 학습시켰기 때문에 정확히 어떤 방식이 모델의 성능에 기여했는지 판별하기 어렵고, 학습의 세부적인 사항을 기술하는 데 어려움이 있다고 합니다.
6. Classification Results
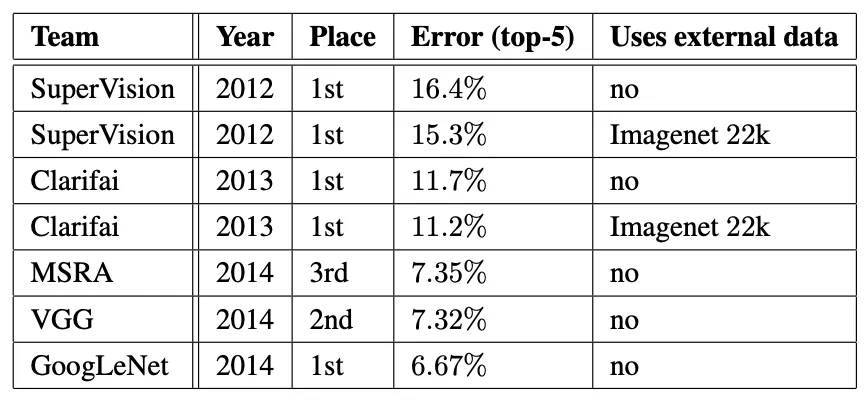
같은 해에 출품한 MSRA, VGG와 비교했을 때 0.65%p 좋은 top-5 error를 기록했습니다. 또한 2012년에 1위를 한 SuperVision과 비교했을 때 약 43% 개선된 성능을 보여주고 있습니다.
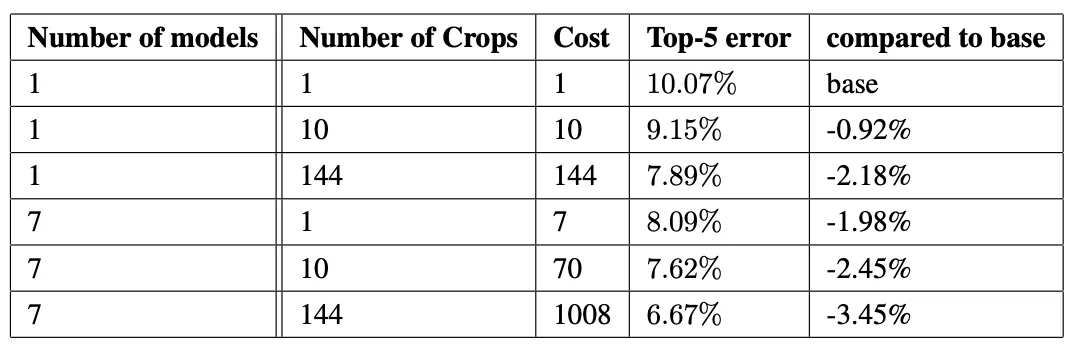
또한 저자들은 7가지 버전의 GoogLeNet 모델을 학습시켰으며, ensemble prediction을 통해 가장 안 좋은(첫 번째) 방식보다 3.4%p (66%) 좋은 top-5 에러를 달성했습니다.
7. Detection Results
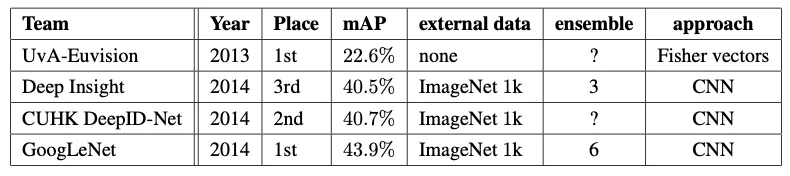
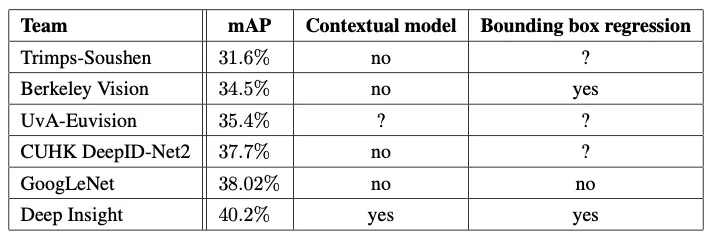
GoogLeNet은 detection에서도 뛰어난 성능을 나타냈습니다. 2위 모델인 DeepID-Net과 비교했을 때, 3.2%p 높은 mAP를 기록했으며, bounding box regression을 사용하지 않고도 디텍션에서 다른 네트워크보다 더 좋은 수치를 나타냈습니다(38.02% mAP).
- Bounding Box Regression
추론 과정에서 바운딩 박스의 좌표를 예측하는 것을 의미합니다. GoogLeNet은 이를 사용하지 않고도 객체를 찾는 과정을 통해서 바운딩 박스의 상대적인 위치를 추측하는 방식으로 동작했습니다.